Naloge
Inventar
Neka trgovina shranjuje svoj inventar v slovarju, katerega ključi so artikli in vrednosti količine:
inv = {'sir': 8, 'kruh': 15, 'makovka': 10, 'pasja radost': 2, 'pašteta': 10, 'mortadela': 4, 'klobasa': 7}
Pazi: vrednosti so števila (npr. 10) in ne nizi ("10").
Napišite funkcijo zaloga(inventar, artikel) naj pove, koliko izdelka
artikel imamo na zalogi. Če bi imeli gornji slovar z inventarjem
shranjen v slovarju inv, mora klic zaloga(inv, "makovka") vrniti
10.
>>> zaloga(inv, "makovka")
10
Rešitev
def zaloga(inventar, artikel):
return inventar[artikel]
Napišite funkcijo prodaj(inventar, artikel, kolicina), ki zmanjša
količino artikla artikel v inventarju inventar za kolicina. Klic
prodaj(inv, "makovka", 3) (prodali smo tri makovke) mora spremeniti
slovar inv tako, da zmanjša vrednost pri ključu "makovke" za 3. Funkcija ne vrača ničesar.
>>> inv
{'sir': 8, 'kruh': 15, 'makovka': 10, 'pasja radost': 2, 'pašteta': 10, 'mortadela': 4, 'klobasa': 7}
>>> prodaj(inv, "makovka", 3)
>>> inv
{'sir': 8, 'kruh': 15, 'makovka': 7, 'pasja radost': 2, 'pašteta': 10, 'mortadela': 4, 'klobasa': 7}
Nasvet: če veš preveč in si že slišal za argumente po vrednosti in po referenci, te misli do nadaljnjega opusti, saj za Python niso relevantne.
Rešitev
def prodaj(inventar, artikel, kolicina):
inventar[artikel] -= kolicina
Napišite funkcijo primanjkljaj(inventar, narocilo), ki prejme dva
slovarja: prvi predstavlja trenutni inventar, drugi pa, kaj neka stranka
naroča; naročilo je predstavljeno s slovarjem enake oblike kot inventar.
Funkcija mora vrniti nov slovar, v katerem bo zapisano, koliko česa
moramo še kupiti, da bomo lahko stranki dobavili vse, kar si želi. Če
bi, recimo, stranka želela tri paštete, devet klobas in eno pivo, mora
funkcija vrniti slovar {"klobasa": 2, "pivo": 1}. Dve klobasi zato,
ker jih imamo sedem, stranka pa jih želi devet. Paštet ne bo potrebno
naročati, saj jih imamo dovolj. Pivo pa potrebujemo, saj nimamo
nobenega.
>>> primanjkljaj(inv, {"pašteta": 3, "klobasa": 9, "pivo": 1})
{"klobasa": 2, "pivo": 1}
Rešitev
def primanjkljaj(inventar, narocilo):
manjka = {}
for artikel, kolicina in narocilo.items():
if kolicina > inventar.get(artikel, 0):
manjka[artikel] = kolicina - inventar.get(artikel, 0)
return manjka
Najpogostejše
Napišite pomožno funkcijo freq(s), ki sestavi in vrne slovar pogostosti črk v nizu s.
>>> freq("abcaad")
{'a': 3, 'b': 1, 'c': 1, 'd': 1}
Napišite pomožno funkcijo max_freq(f), ki vrne ključ v slovarju f z največjo shranjeno vrednostjo.
>>> max_freq({'a': 3, 'b': 1, 'c': 1, 'd': 1})
'a'
Napišite funkcijo najpogostejse(s), ki vrne besedo in znak, ki se v
podanem nizu največkrat pojavita. V nizu 'in to in ono in to smo mi'
se največkrat pojavita beseda 'in' in znak ' ' (presledek).
>>> najpogostejse('aa bb aa')
('aa', 'a')
>>> najpogostejse('in to in ono in to smo mi')
('in', ' ')
Rešitev
Preštejemo število ponovitev elementov seznama xs.def freq(xs):
hist = {}
for x in xs:
if x not in hist:
hist[x] = 0
hist[x] += 1
return hist
def max_freq(f):
max_freq = 0
max_item = None
for item, item_freq in f.items():
if item_freq > max_freq:
max_freq = item_freq
max_item = item
return max_item
def najpogostejse(s):
return max_freq(freq(s.split())), max_freq(freq(s))
Tisti, ki se ob teh nalogah dolgočasijo, naj napišejo še funkcijo najpogostejse_urejene,
ki vrne vse besede in črke, ki se v podanem nizu pojavijo, urejene po
številu pojavitev (besede in črke z enakim številom pojavitev uredite po
abecednem vrstnem redu).
>>> najpogostejse_urejene('aa bb aa')
(['aa', 'bb'], ['a', ' ', 'b'])
>>> najpogostejse_urejene('in to in ono in to smo mi')
(['in', 'to', 'mi', 'ono', 'smo'], [' ', 'o', 'i', 'n', 'm', 't', 's'])
Rešitev
def freq(xs):
hist = {}
for x in xs:
if x not in hist:
hist[x] = 0
hist[x] += 1
return hist
def max_sorted(f):
xs = []
for k, v in f.items():
xs.append((-v, k))
xs.sort()
ys = []
for k, v in xs:
ys.append(v)
return ys
def najpogostejse_urejene(s):
return max_sorted(freq(s.split())), max_sorted(freq(s))
Naključno generirano besedilo
Napisati želimo program, ki bo naključno generiral besedilo. Seveda ni
dobro, da si samo naključno izbiramo besede in jih lepimo skupaj, saj bi
tako dobili nekaj povsem neberljivega. Naloge se bomo lotili malo
pametneje. Recimo, da ima program na voljo nek tekst
('in to in ono smo mi'), iz katerega se lahko uči. Naš naključni tekst
bomo začeli s poljubno besedo, recimo to. Nadaljujemo tako, da se
vprašamo katere besede se v učnem tekstu pojavijo za besedo to. V
našem primeru je to samo beseda in. Postopek nato ponovimo z besedo
in. Če kakšni besedi v učnem tekstu sledi več kot samo ena beseda,
izberemo naključno (glej funkcijo choice iz modula random, ki vrne naključno besedo iz podanega seznama). Naloge se bomo lotili po korakih:
Napišite funkcijo nasledniki(txt), ki za vsako besedo b v nizu txt
zgradi seznam besed, ki v tekstu nastopijo za besedo b. Nekaj
primerov:
>>> nasledniki('in in in in')
{'in': ['in', 'in', 'in']}
Za besedo in se na treh mestih pojavi beseda in.
>>> nasledniki('in to in ono in to smo mi')
{'smo': ['mi'], 'to': ['in', 'smo'], 'ono': ['in'], 'in': ['to', 'ono', 'to']}
Za besedo smo se pojavi samo beseda mi, medtem ko se recimo za
besedo to pojavita tako beseda smo kot tudi beseda in.
Rešitev
import collections
def nasledniki(txt):
words = txt.split()
freq = collections.defaultdict(list)
for word, next_word in zip(words, words[1:]):
freq[word].append(next_word)
return freq
Sedaj pa napišite še funkcijo tekst(nasl, num_besed), ki sprejme
slovar, ki ga ustvari funkcija nasledniki in generira naključno
besedilo dolgo num_besed besed.
Vaš program lahko testirate na Orwellovi noveli.
>>> import urllib.request
>>> txt = urllib.request.urlopen('http://squeeb1134.tripod.com/1984.txt').read().decode('utf8')
>>> tekst(nasledniki(txt), 20)
'Big Brother had been drained out of the hands of me for his heart banged, seeming to grow less. Always'
Zaradi naključnosti je nalogo tekst težko preveriti z unittesti.
Priložen test preveri le najbolj osnovne lastnosti.
Rešitev
import random
def tekst(freq, besed):
words = []
all_words = list(freq.keys())
word = random.choice(all_words)
for i in range(besed):
words.append(word)
word = random.choice(freq.get(word, all_words))
return ' '.join(words)
Družinsko drevo
V seznamu family je spravljeno družinsko drevo:
family = [('bob', 'mary'), ('bob', 'tom'), ('bob', 'judy'), ('alice', 'mary'),
('alice', 'tom'), ('alice', 'judy'), ('renee', 'rob'), ('renee', 'bob'),
('sid', 'rob'), ('sid', 'bob'), ('tom', 'ken'), ('ken', 'suzan'), ('rob', 'jim')]
V vsaki terki sta zapisani dve imeni: ime starša in ime otroka. Terka
('bob', 'mary') nam pove, da je Bob Maryjin oče, terka
('bob', 'tom') pa, da je Bob Tomov oče, itd.
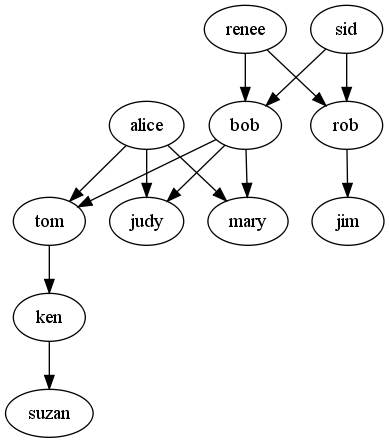
Napišite funkcijo family_tree(family), ki sprejeme seznam v kateri je
spravljeno družinsko drevo in vrne slovar v katerem je za vsakega starša
spravljen seznam vseh njegovih otrok.
>>> family_tree(family)
{'renee': ['rob', 'bob'], 'ken': ['suzan'], 'rob': ['jim'], 'sid': ['rob', 'bob'], ... , 'bob': ['mary', 'tom', 'judy']}
Rešitev
def family_tree(family):
tree = {}
for parent, child in family:
if parent not in tree:
tree[parent] = []
tree[parent].append(child)
return tree
import collections
def family_tree(family):
tree = collections.defaultdict(list)
for parent, child in family:
tree[parent].append(child)
return tree
Napišite funkcijo children(tree, name), ki v družinskem drevesu tree
vrne seznam vseh otrok osebe. V primeru, da oseba nima otrok vrnite
prazen seznam.
>>> tree = family_tree(family)
>>> children(tree, 'alice')
['mary', 'tom', 'judy']
>>> children(tree, 'mary')
[]
Rešitev
def children(tree, name):
if name in tree:
return tree[name]
return []
def children(tree, name):
return tree.get(name, [])
Napišite funkcijo grandchildren(tree, name), ki vrne seznam vseh
vnukov in vnukinj osebe.
>>> grandchildren(tree, 'renee')
['jim', 'mary', 'tom', 'judy']
Rešitev
def grandchildren(tree, name):
names = []
for child in children(tree, name):
for grandchild in children(tree, child):
names.append(grandchild)
return names
def grandchildren(tree, name):
names = []
for child in children(tree, name):
names.extend(children(tree, child))
return names
Naslednja funkcija je malo zahtevnejša od ostalih, zato jo lahko
preskočite. Napišite funkcijo successors(tree, name), ki vrne seznam
vseh naslednikov osebe.
>>> successors(tree, 'tom')
['ken', 'suzan']
>>> successors(tree, 'sid')
['rob', 'bob', 'jim', 'mary', 'tom', 'judy', 'ken', 'suzan']
Rešitev
Nalogo lahko rešimo rekurzivnodef successors(tree, name):
names = []
for child in children(tree, name):
names.append(child)
names.extend(successors(tree, child))
return names
def successors(tree, name):
names = []
todo = [name]
while todo:
cs = children(tree, todo.pop())
names.extend(cs)
todo.extend(cs)
return names
def successors(tree, name):
names = [name]
for n in names:
names.extend(children(tree, n))
return names[1:]
Šifra
Niz
'\x19\x14\x1c]\x19\x0f\x14\t\x13\x18\t]\x12\x0e[\n\x1a\t\x18\x15\x12\x13\x1c'
lahko odšifriramo z naslednjo funkcijo:
def sifriraj(niz, kljuc):
return ''.join(chr(ord(c) ^ (kljuc // 256**(i % 2) % 256)) for i, c in enumerate(niz))
Problem je v tem, da ne poznamo ključa. Vemo le, da je nekje med 0 in
65536. Sumimo, da je originalno sporočilo v angleškem jeziku in da so
vse besede slovnično pravilno zapisane. Napišite funkcijo sifra(niz),
ki vrne odšifrirano sporočilo.
>>> sifriraj('strawberry pudding', 1337)
'JqKdNg\\wK|\x19uLa]lWb'
>>> sifriraj('JqKdNg\\wK|\x19uLa]lWb', 1337)
'strawberry pudding'
>>> sifra('JqKdNg\\wK|\x19uLa]lWb') # To funkcijo morate napisati vi
'strawberry pudding'
Namig:
- Funkcije
sifrirajvam ni treba razumeti. - Pomagajte si s seznamom angleških
besed. Preberete ga lahko z
besede = [w for w in open("Usr.dict.words")]; po tem bodobesedeseznam besed, vendar bi ga bilo mogoče smiselno takoj predelati v kaj bolj uporabnega.
Rešitev
def sifra(niz):
# Zgradimo množico vseh angleških besed.
words = set()
with open('Usr.Dict.Words') as f:
for word in f:
words.add(word.strip())
# Sprehodimo se po vseh možnih ključih.
for k in range(65536):
plain = sifriraj(niz, k)
for w in plain.split():
if w not in words:
break
else:
return plain